
iText veröffentlicht Open-Source-Produkt »iText pdfOCR«
24871-iText-PDF-OCR
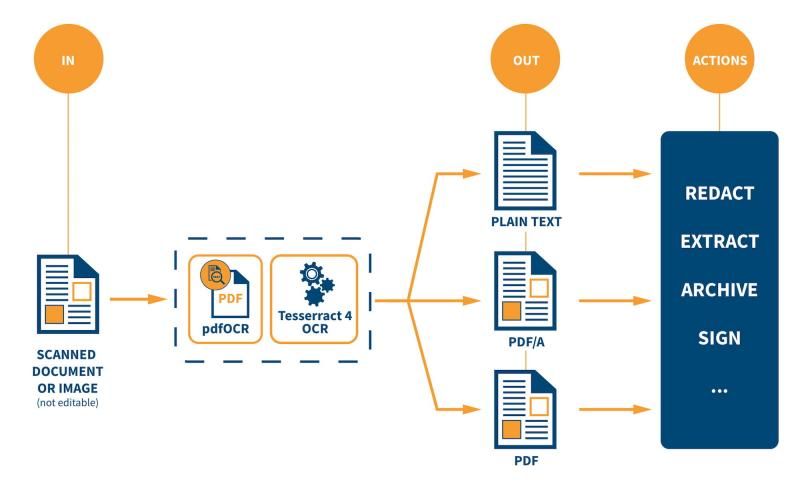
Funktionsweise des Open-Source-OCR-Moduls » iText pdfOCR« (Grafik: iText Group)
Das belgische Unternehmen iText Group hat für sein PDF-SDK »iText 7« mit »iText pdfOCR« eine optische Zeichenerkennung (OCR) entwickelt. Sie steht ab sofort zur Verfügung und ermöglicht es, gedruckten Text in eingescannten Dokumenten und Bildern in vollständig durchsuchbare Formate (PDF Version 1.7) umzuwandeln. Die erzeugten Formate eignen sich für Langzeitarchivierung und sind vollständig kompatibel zum PDF/A-3u-Standard. Als Anwendungsbereiche sieht der Entwickler zum Beispiel die Archivierung historischer Dokumente, die Übersetzung von juristischen Texten, die automatische Eingabe von Daten bei allen Arten von Bewerbungen oder Forderungen auf Basis von Papierdokumenten sowie die Sortierung von gedruckten oder gescannten Dokumenten, die bislang nicht editierbar waren.
Die Itext Group empfiehlt nach dem Einlesen weitere, eigene Produkte einzusetzen, um komplette Workflows abzubilden. So lassen sich mit »iText pdf2Data« Daten extrahieren, mit »iText pdfSweep« Inhalte schwärzen oder mit »iText pdfCalligraph« mehrsprachige Dokumente erstellen. Zur Weiterverwendung der extrahierten Daten empfiehlt das Unternehmen den Dokumentengenerator »iText DITO«.
PDF/A-Konformitätslevel 3u
Das sogenannte Konformitätslevel 3u verlangt ebenso wie PDF/A Unicode-Mapping einzelner Schriftzeichen. Allerdings lässt es Anforderungen von PDF/A in Bezug auf die Übernahme der den Dokumenten innewohnenden logischen Struktur vermissen, wie sie in Absatz 6.7 von ISO 19005-2 (PDF 1.7) spezifiziert sind. Nichtsdestotrotz können die erkannten Zeichen zuverlässig durchsucht und kopiert werden, lediglich die Reihenfolge der einzelnen Textbestandteile kann nicht gewährleistet werden. Dafür kann PDF/A-3u durch eingebettete Dateien beliebiger Art ergänzende Beschreibungen vermitteln.
OCR-Engine Tesseract von HP als Basis
Das neu vorgestellte OCR-Add-On basiert auf der Technologie der »Tesseract-OCR-Engine. Tesseract wurde ursprünglich bereits 1985 von Hewlett-Packard entwickelt, 2005 mit einer Apache-Open-Source-Lizenz veröffentlicht und unterstützt inzwischen mehr als 100 Sprachen. Seit 2006 wird die Entwicklung von Google gefördert.
»Die OCR-Fähigkeiten von Itext pdfOCR eröffnen viele Chancen und Möglichkeiten für Anwender und Unternehmen, die ihr Datenpotenzial maximieren möchten«, sagt Yeonsu Kim, Geschäftsführer bei Itext Group NV. »Da wir unsere Open-Source-Vergangenheit nicht vergessen möchten, basiert Itext pdfOCR auf der Tesseract-OCR-Engine, die ebenfalls in Open-Source vorliegt. Damit möchten wir betonen, dass wir nach wie vor ein Open-Source-Unternehmen sind. Diesen Wert schätzen unsere Millionen von Anwendern und Kunden gleichermaßen.«
Zusätzliche Daten nutzbar machen
»Dieses neue Produkt in unserer PDF-Bibliothek hilft Entwicklern dabei, Daten zu nutzen, die bislang in nicht zugänglichen Dokumenten verborgen lagen. Mit unserem neuesten Produkt können diese Unternehmen ihren digitalen Workflow erweitern, indem sie auf Daten aus eingescannten Dokumenten zugreifen und sie für ihre Zwecke oder die ihrer Endbenutzer verwenden«, sagt Tony Van den Zegel, VP im Bereich Produkte und Marketing, bei Itext Group.
Über die Möglichkeiten seines neuen Produkts informiert iText am 9. Juli 2020 mittels mehreren Online-Live-Vorführungen. Vorab angemeldeten Interessenten steht anschließend auch eine Aufzeichnung zur Verfügung.
Eigenen Angaben zufolge kann Itext auf weltweit 125 Millionen Anwender seiner Software verweisen. Das Unternehmen hat mittlerweile 18 Produkte im Portfolio und besteht seit 20 Jahren. Zu den Kunden gehören unter anderem Dell, IBM, Microsoft, aber auch Axa, Wolters Kluwer, Deutsche Bank, Siemens und Zeiss. Seinen Hauptsitz hat das Unternehmen in Belgien, weitere Standorte in Singapur, Südkorea und den USA (Boston).